Use a binary search for the needed Attribute.
Also moved the implementation from the header.
From 76,84% of cpu
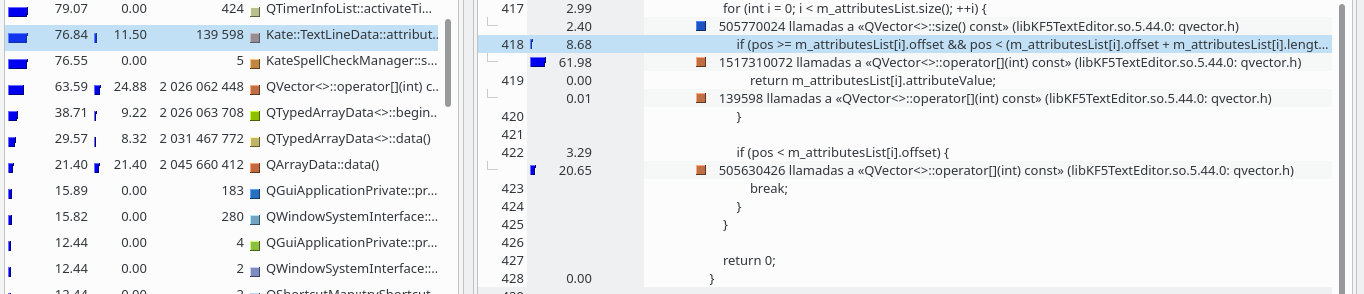
to 0.08% of cpu

in callgrind doing the following:
Open an XML file with 4 lines and a line of 566039 characters long.
Accept to reopen the file, move to the end of the file (ctrl+end), and close.
The time difference can also be noticed in the autotests.