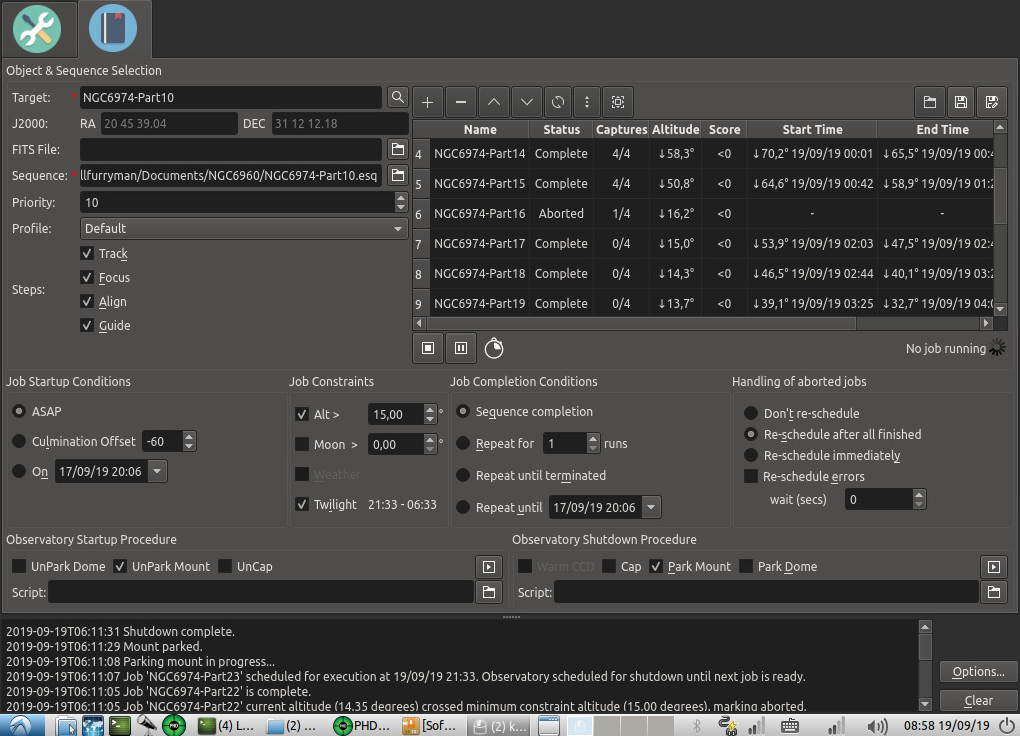
Currently, the Scheduler is not very robust against temporary problems during an imaging session. Passing clouds might create situations, where either the Scheduler terminates or the different modules get out of sync with there state. As a result, some passing clouds can destroy an entire session.
This patch adds the option to control, how the Scheduler should handle aborted jobs:
- Try to restart them directly after a configurable delay.
- Continue with the other scheduled jobs. As soon as no jobs are scheduled, try to restart the aborted jobs (current behaviour, but with the additional option of a configurable delay).
- Do not restart aborted jobs at all.
Additionally, there is an option to handle errors like aborted jobs and try to restart them. Whether selecting this option depends on the individual technical setup. In my case, I experience from time to time errors when slewing to a target. Restarting it does not create any problem at all. But it might be the case, that with other setups its dangerous to ignore an error and expose the equipment to the same error situation again and again. That's why I added this as an option.
Third thing that I changed is re-sorting error jobs at the end of the schedule. This only makes sense if we do not want to restart them. Otherwise, re-sorting them disturbs the intentionally set order of jobs. Therefore, I disabled this feature.
Last thing: there were some guiding and focusing problems that led to an error state. I changed their result to the aborted state.