Problem statement
While most aspects of the scheme are working well, there are a few parts which are problematic. As all these require changes to the DB, support for all items should be preferably done with a single database version bump/migration.
document ID
The document ID is a 64 bit integer, used to represent each file/document/directory uniquely. Currently, it is created as a concatenation of the inodes st_dev and st_ino structure fiels (man 7 inode, stat.st_dev and stat.st_ino). From each field, the lower 32 bit are used, and used as high and low half.
Problems with this scheme:
- Contemporary file systems use 64 bit inode numbers (XFS, BTRFS, EXT4 (optionally))
- st_dev is not stable. For disks, it uses the devices major/minor number, i.e. moving the disk to a different controller will change the device. For network FSs and disk images, it is not stable at all and depends on the mount order.
- The inode bits are put in the high part (endian dependent? at least for LE). documentIDs are in some places coded differentially for storage efficiency (e.g. by the document terms db), which does not work well as the mostly static part (device id) is in the low bits and the differing part (inode) in the high bits, i.e. each difference is at least 2^32.
position db
For each (search) term not only the documentID is stored, but also the position (also the frequency / number of occurences is calculated, but not stored).
Example: The quick brown fox jumps over the not so quick dog 'the' : [1, 7] 'quick' : [2, 10] 'brown': [3] ...
The DB entries are keyed by term, the value is composed as [ `documentID : number of positions : [positions] ] , concatenated for all matching documents.
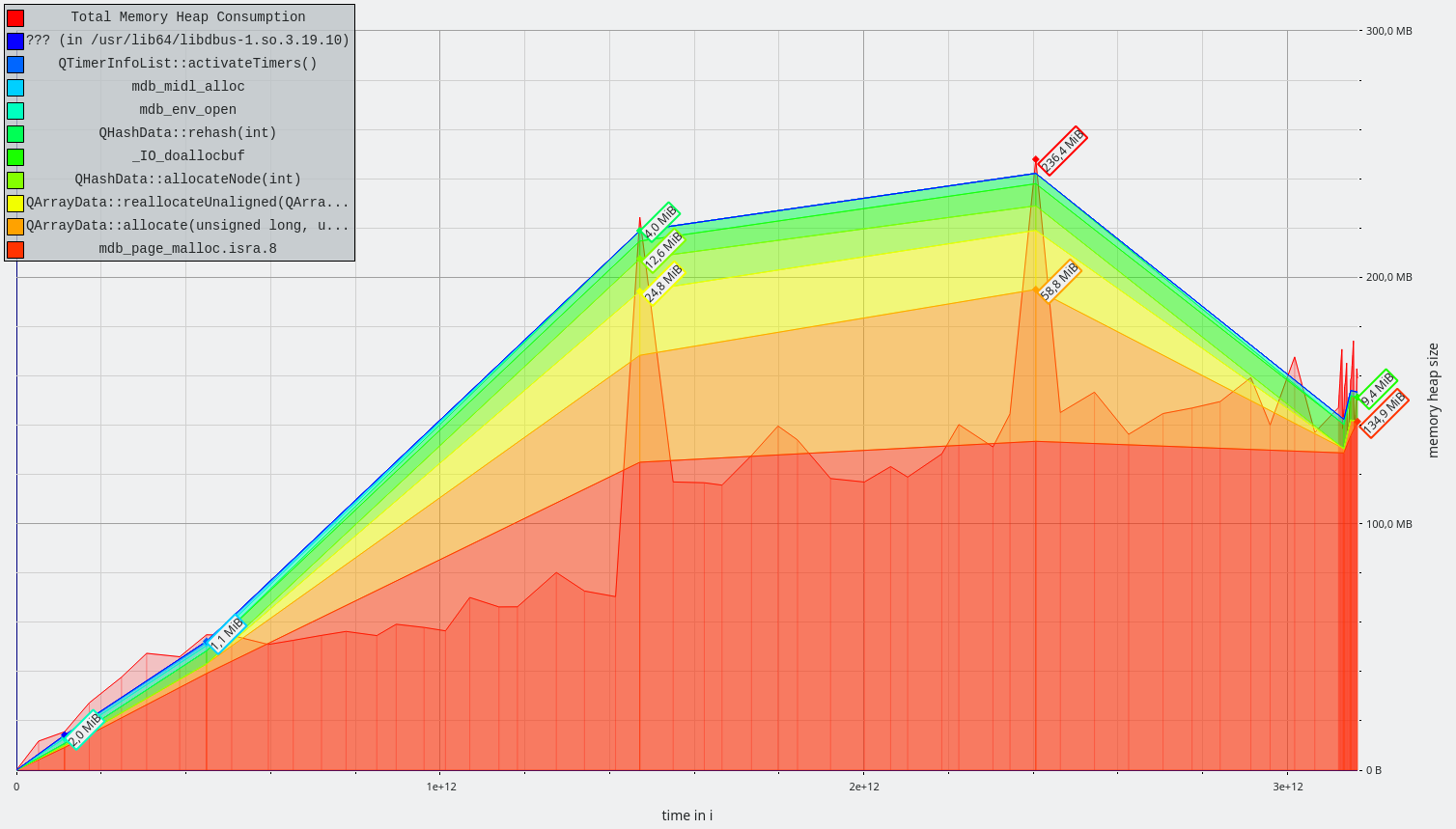
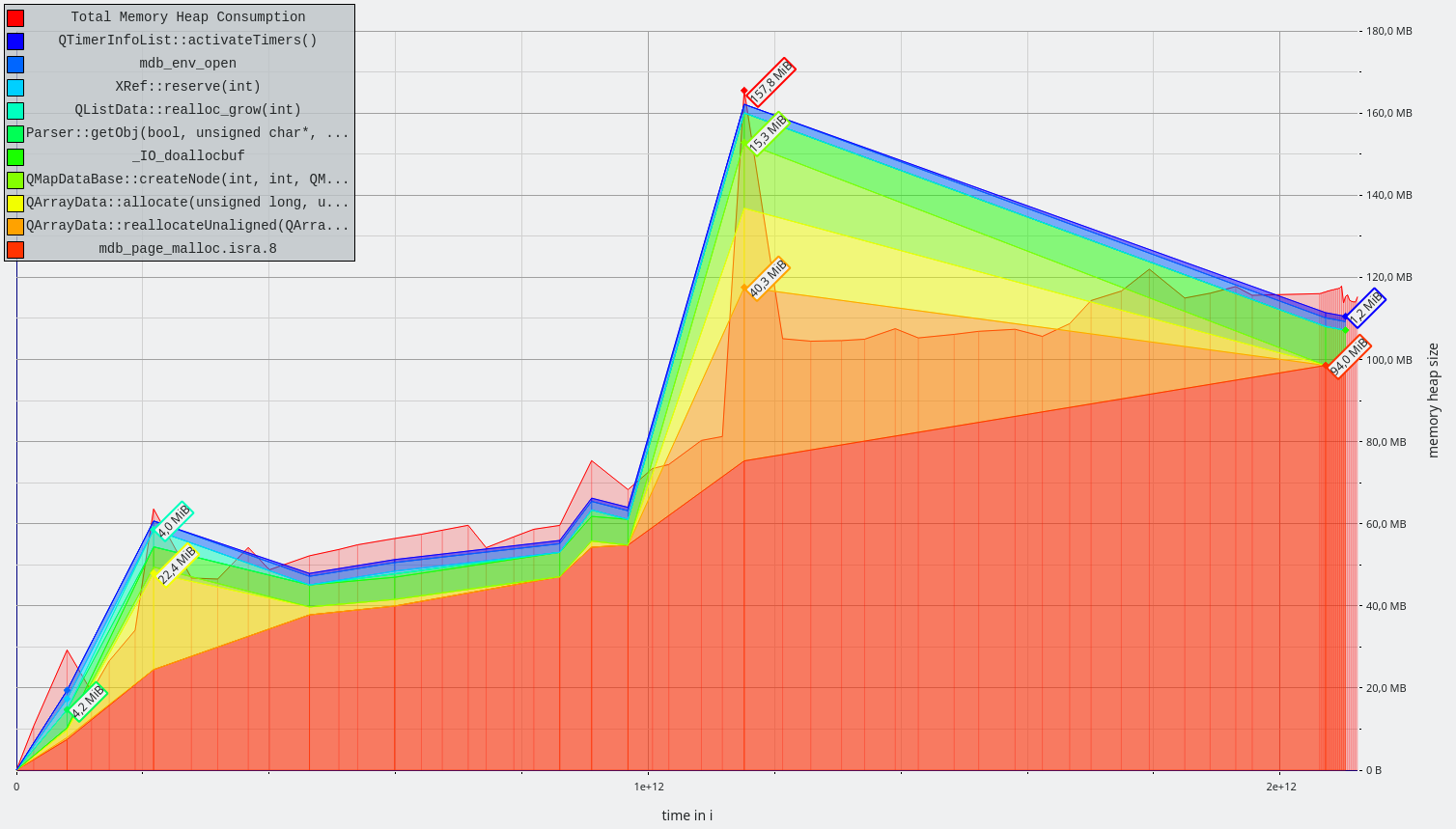
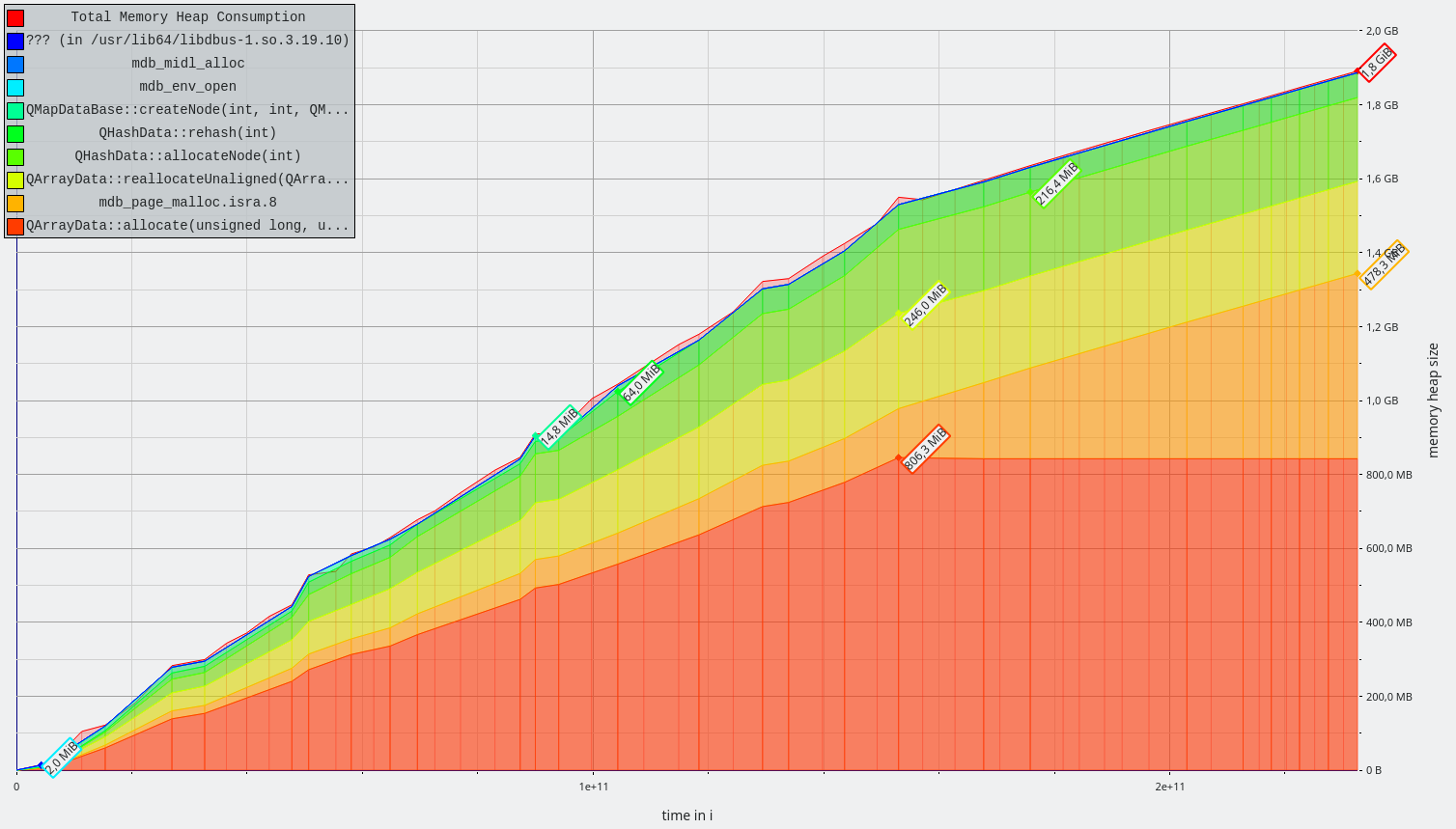
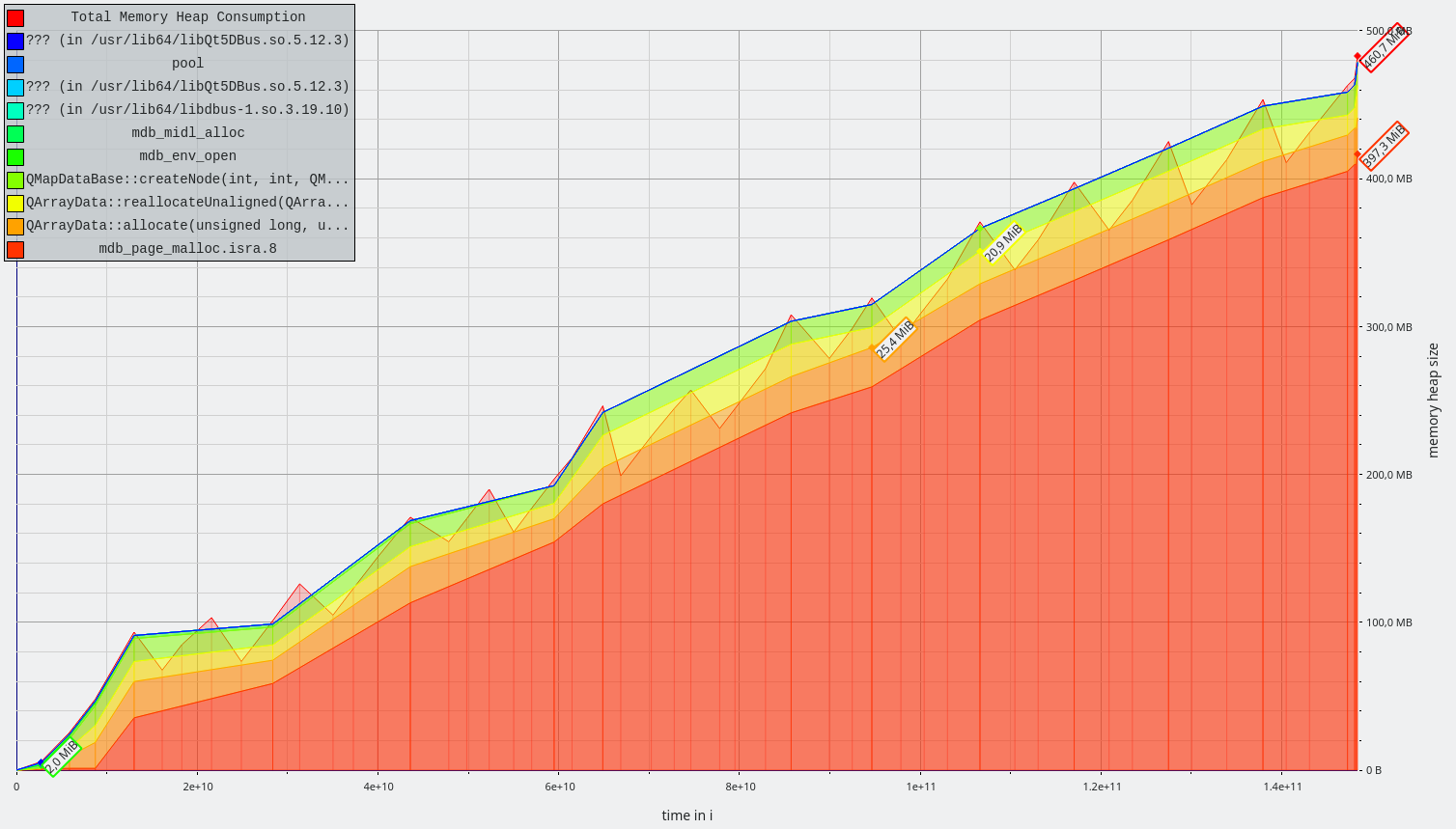
E.g. adding one document with only 5 terms requires rewriting 5 DB entries, each a costly read-decode-insert-encode-write cycle. Large documents with many terms can trigger a rewrite of a significant portion of the DB.
extractor tracking
Each time a new extractor is added or enhanced (possibly extracting new data), the DB only contains the old data. (T8079).
Solution proposal
document ID
- use one database file per device
- store the db file either on the same device as the tracked files
- or/and
- store an identifier per tracked device, e.g the filesystem UUID
- only store the inode inside the DB (64 bit)
This scheme also allows storing indexes on removable media or inside encrypted containers.
position db
a) remove the position DB alltogether
or
b) use the document ID as key, store terms and positions as value
Regarding (a), the position DB is hardly used. The match decision is already possible using the terms DB only. For filenames, "phrase" matches are still possible as filenames are stored verbatim.
(b) avoids the RMW cycles when documents are changed. The storage size stays the same. Matching is much simpler, as the first matching step of the andPositionIterator can be replaced by a single database lookup.
Extractors
- assign a version number to each extractor
- store the used version on first use
- on version increase, reindex all affected files
- update the stored version