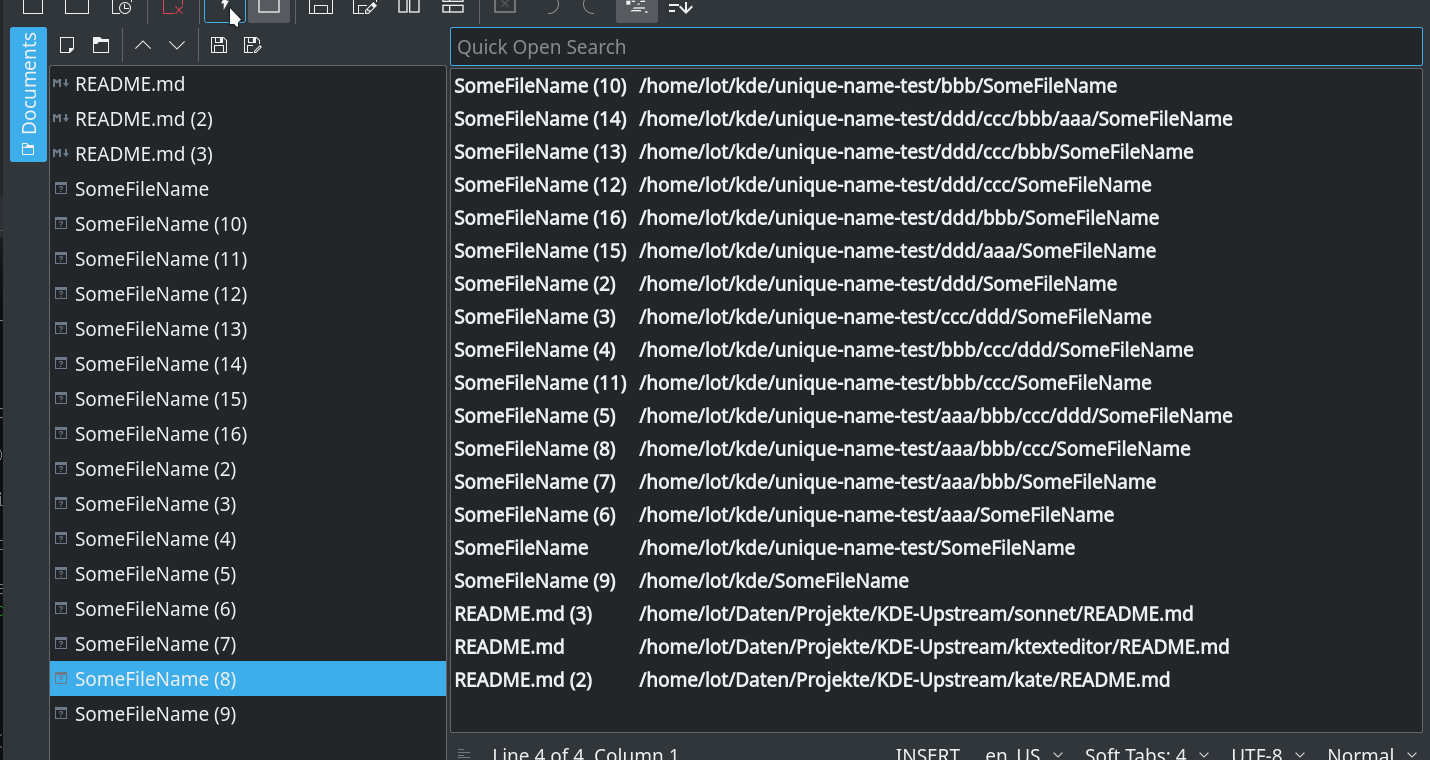
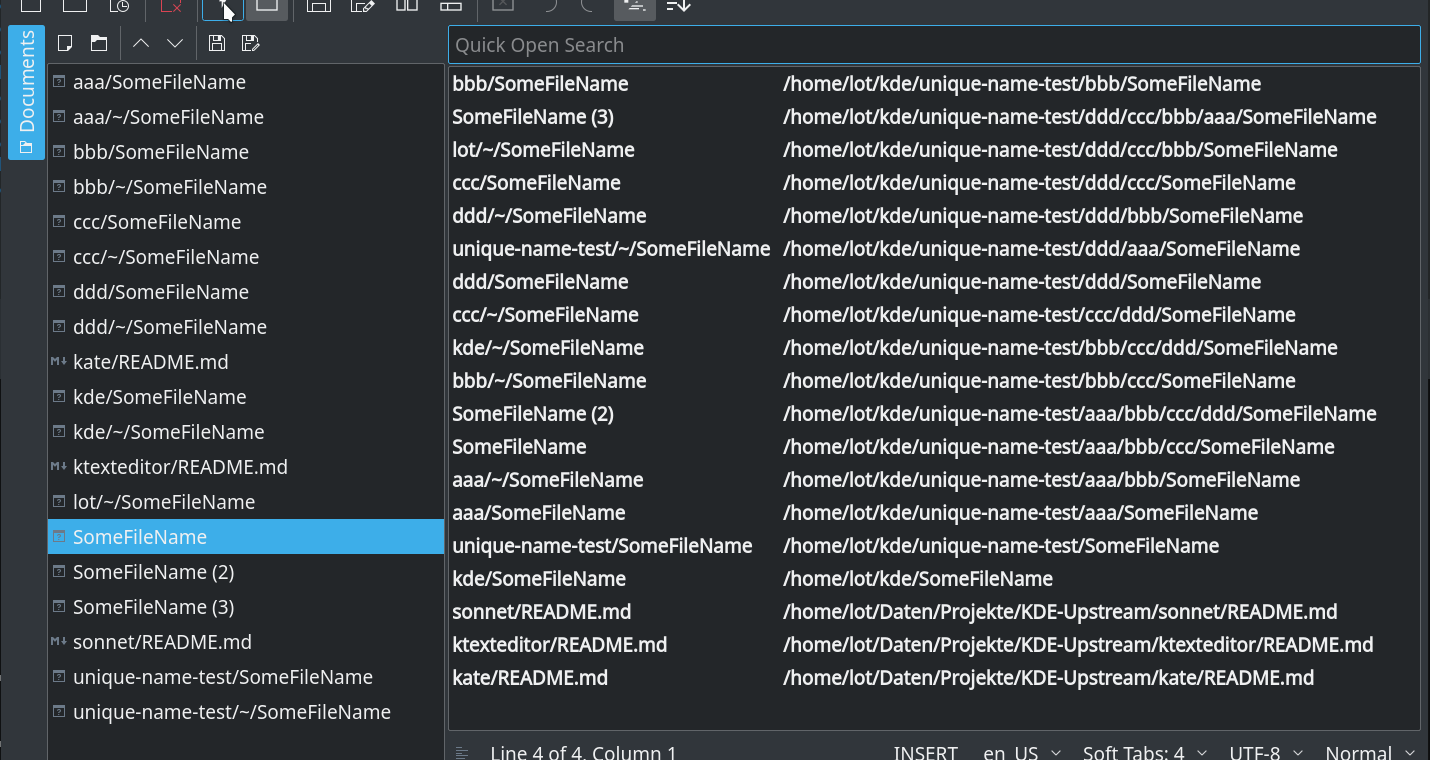
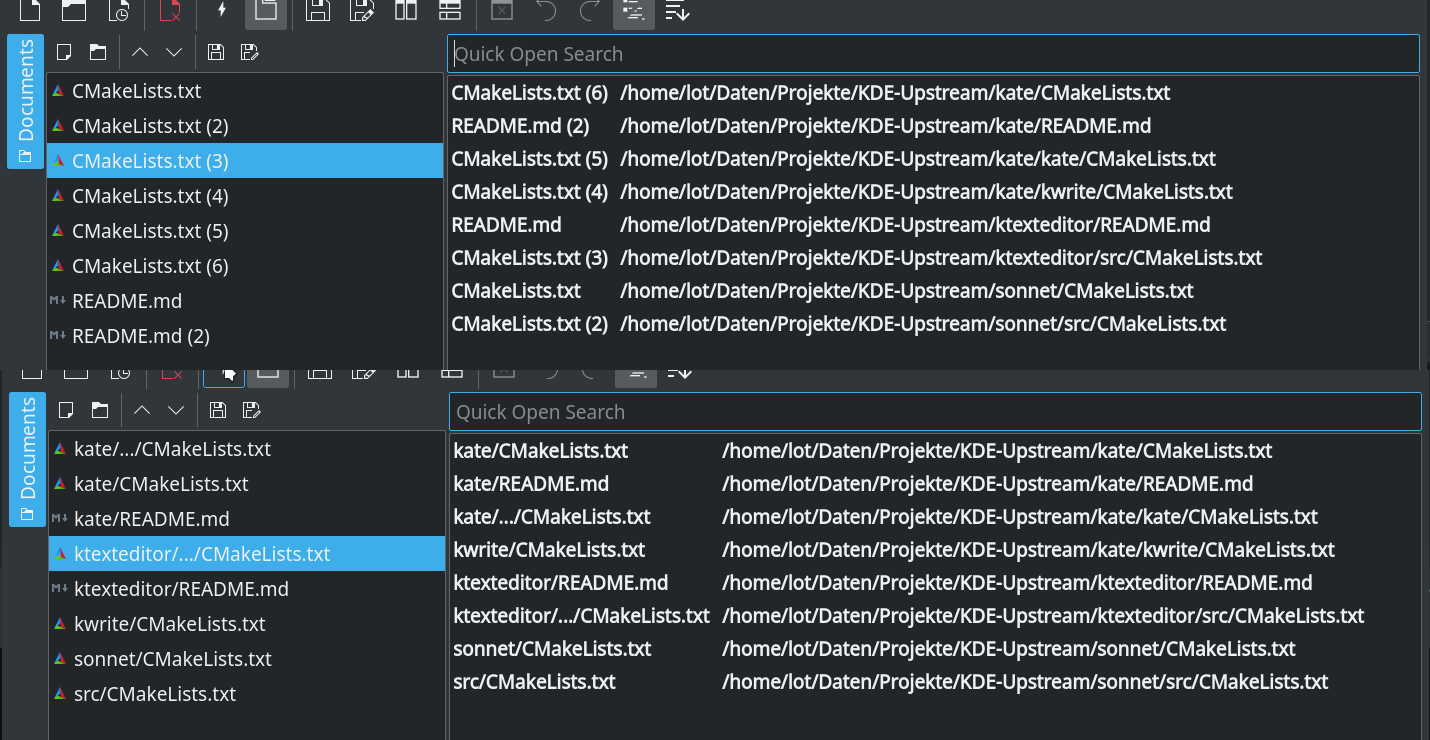
When you e.g. work on multiple projects at the same time you have often the case that you have documents with a number suffix on tabs or other places like side bars. These suffix give no hint which file it really is.
This patch add some folder name to the document to make the name unique, which should be in any case more helpful than the number suffix.
Drawbacks
- The unique names can change when you open a file
- The numbering is kept as fallback for rare cases. When it is in use are these numbers also not "static" like in case of "Untitled" documents